

What Is a Robots.txt File?
Arobots.txt train is a set of instructions used by websites to tell hunt machines which runners should and shouldn’t be crawled.Robots.txt lines companion straggler access but shouldn’t be used to keep runners out of Google’s indicator.
A robots.txt file looks like this:
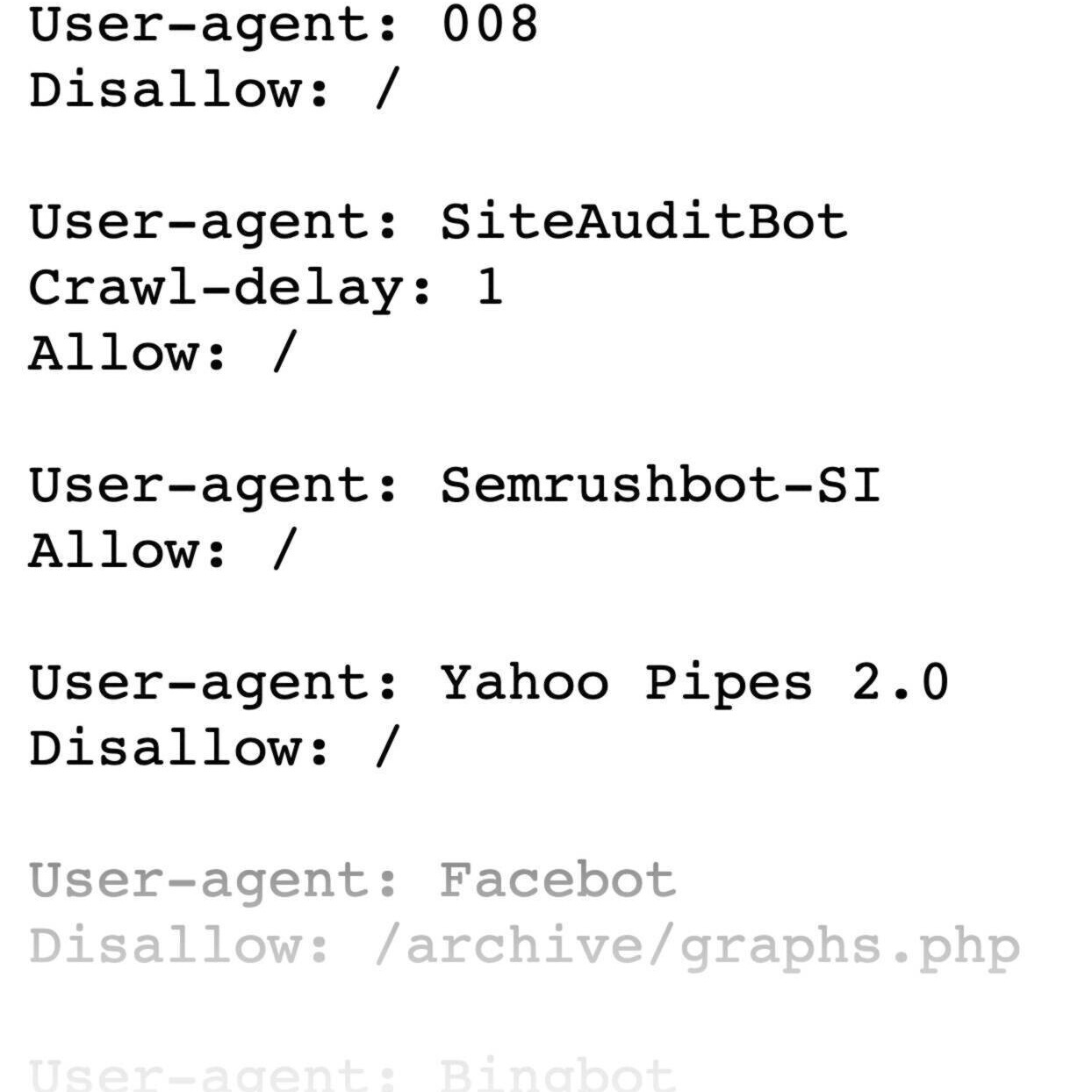
Robots.txt files might seem complicated, but the syntax (computer language) is straightforward. We’ll get into those details later.
In this article we’ll cover:
- Why robots.txt lines are important
- How robots.txt lines work
- How to produce a robots.txt train
- stylish practices
Why Is Robots.txt Important?
A robots.txt train helps manage web straggler conditioning so they do n’t outrun your website or indicator runners not meant for public view.
Below are a few reasons to use a robots.txt file:
Optimize Crawl Budget
Bottleneck budget refers to the number of runners Google will crawl on your point within a given time frame.
The number can vary grounded on your point’s size, health, and number of backlinks.
still, you could have unindexed runners on your point, If your website’s number of runners exceeds your point’s bottleneck budget.
Unindexed runners wo n’t rank, and eventually, you ’ll waste time creating runners druggies wo n’t see.
Blocking gratuitous runners withrobots.txt allows Googlebot( Google’s web straggler) to spend further bottleneck budget on runners that count.
Note utmost website possessors don’t need to worry too important about bottleneck budget, according to Google. This is primarily a concern for larger spots with thousands of URLs.
Block Duplicate and Non-Public Pages
Bottleneck bots don’t need to sift through every runner on your point. Because not all of them were created to be served in the Search Engine Results Pages( SERPs).
Like staging spots, internal Search results pages, indistinguishable Pages, or login pages.
Some content manamanagement systems handle these internal pages for you.
WordPress, for example, automatically disallows the login pages/ wp- admin/ for all crawlers.
allows you to block these pages from crawlers.
Hide Resources
Occasionally you want to count resources similar as PDFs, videos, and images from search results.
To keep them private or have Google focus on more important content.
In either case,robots.txt keeps them from being crawled (and thus listed).
How Does a Robots.txt File Work?
Robots.txt files tell search engine bots which URLs they can crawl and, more importantly, which ones to ignore.
Search engines give two main purposes:
- Crawling the web to discover content
- Indexing and delivering content to searchers looking for information
As they crawl webpages, search engine crawlers discover and follow links. This process takes them from site A to site B to site C across millions of links, pages, and websites.
But if a bot or crawler finds a robots.txt file, it will read it before doing anything else.
The syntax is straightforward.
Assign rules by identifying the user-agent (the search engine bot), followed by the directives (the rules).
You can also use the asterisk (*) to assign directives to every user-agent, which applies the rule for all bots.
For example, the below instruction allows all bots except DuckDuckGo to crawl your site:
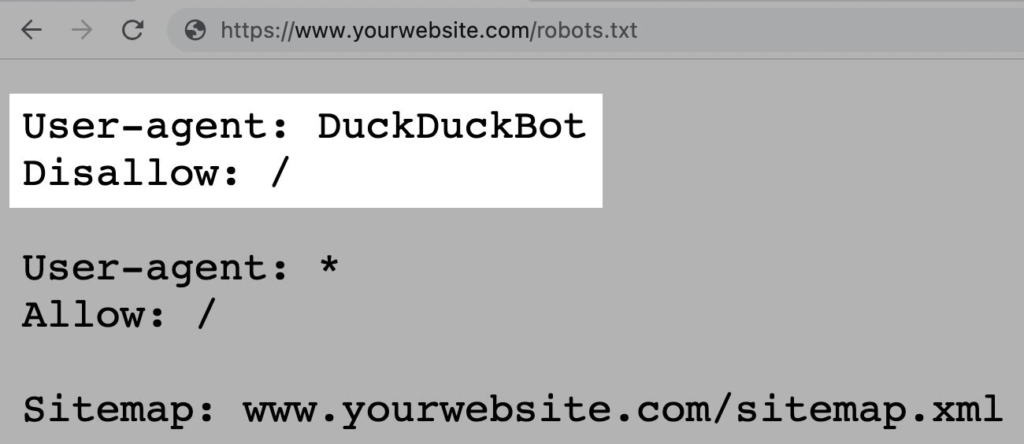
Note: Although a robots.txt file provides instructions, it can’t enforce them. Think of it as a code of conduct. Good bots (like search engine bots) will follow the rules, but bad bots (like spam bots) will ignore them.
How to Find a Robots.txt File
The robots.txt file is hosted on your server, just like any other file on your website.
View the robots.txt file for any given website by typing the full URL for the homepage and adding “/robots.txt” at the end.
Like this: https://skbdevhttp://skbdev.com/robots.txt.com/robots.txt.
Note: A robots.txt file should always live at the root domain level. For www.example.com, the robots.txt file lives at www.example.com/robots.txt. Place it anywhere else, and crawlers may assume you don’t have one.
Before learning how to create a robots.txt file, let’s look at their syntax.
Robots.txt Syntax
A robots.txt file is made up of:
- One or more blocks of “directives” (rules)
- Each with a specified “user-agent” (search engine bot)
- And an “allow” or “disallow” instruction
A simple block can look like this:
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.yourwebsite.com/sitemap.xmlThe User-Agent Directive
The first line of every directives block is the user-agent, which identifies the crawler.
If you want to tell Googlebot not to crawl your WordPress admin page, for example, your directive will start with:
User-agent: Googlebot
Disallow: /wp-admin/Note: Most search engines have multiple crawlers. They use different crawlers for standard indexing, images, videos, etc.
When multiple directives are present, the bot may choose the most specific block of directives available.
Let’s say you have three sets of directives: one for *, one for Googlebot, and one for Googlebot-Image.
If the Googlebot-News user agent crawls your site, it will follow the Googlebot directives.
On the other hand, the Googlebot-Image user agent will follow the more specific Googlebot-Image directives.
The Disallow Robots.txt Directive
The second line of a robots.txt directive is the “Disallow” line.
You can have multiple disallow directives that specify which parts of your site the crawler can’t access.
An empty “Disallow” line means you’re not disallowing anything—a crawler can access all sections of your site.
For example, if you wanted to allow all search engines to crawl your entire site, your block would look like this:
User-agent: *
Allow: /If you wanted to block all search engines from crawling your site, your block would look like this:
User-agent: *
Disallow: /Note: Directives such as “Allow” and “Disallow” aren’t case-sensitive. But the values within each directive are.
For example, /photo/ is not the same as /Photo/.
Still, you often find “Allow” and “Disallow” directives capitalized to make the file easier for humans to read.
The Allow Directive
The “Allow” directive allows search engines to crawl a subdirectory or specific page, even in an otherwise disallowed directory.
For example, if you want to prevent Googlebot from accessing every post on your blog except for one, your directive might look like this:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/example-postNote: Not all search engines recognize this command. But Google and Bing do support this directive.
The Sitemap Directive
The Sitemap directive tells search engines—specifically Bing, Yandex, and Google—where to find your XML sitemap.
Sitemaps generally include the pages you want search engines to crawl and index.
This directive lives at the top or bottom of a robots.txt file and looks like this:
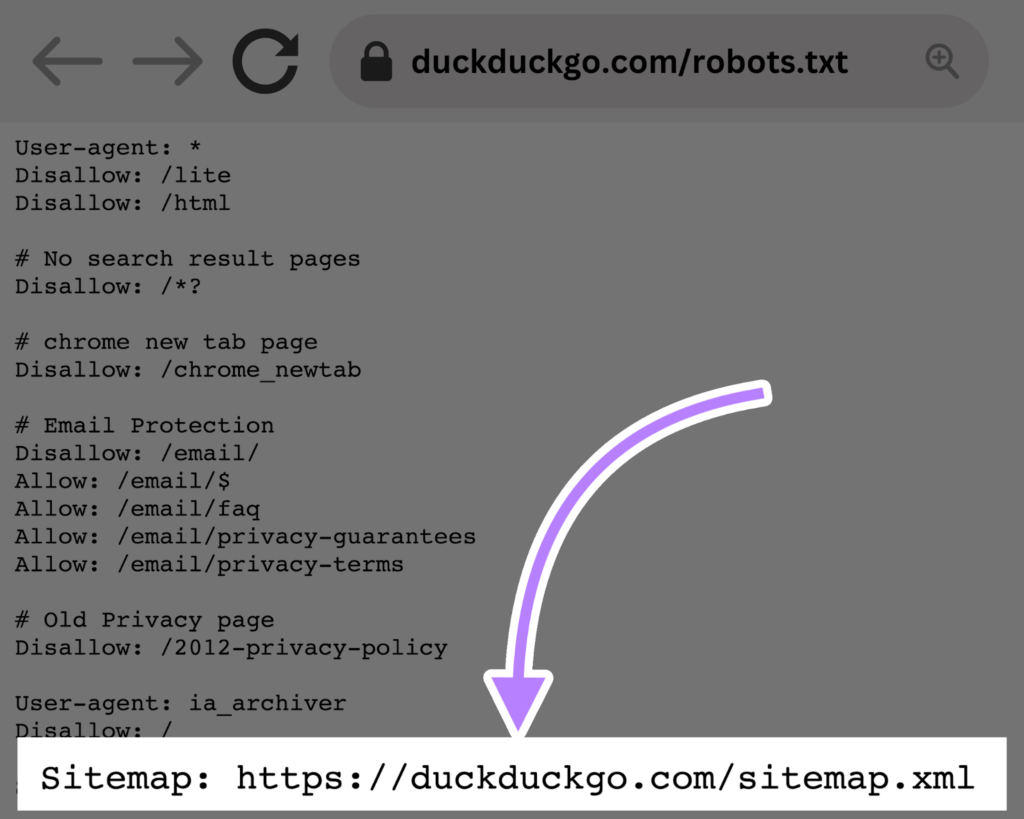
Adding a Sitemap directive to your robots.txt file is a quick alternative. But, you can (and should) also submit your XML sitemap to each search engine using their webmaster tools.
Search engines will crawl your site eventually, but submitting a sitemap speeds up the crawling process.
Crawl-Delay Directive
The crawl-delay directive instructs crawlers to delay their crawl rates. To avoid overtaxing a server (i.e., slow down your website).
Google no longer supports the crawl-delay directive. If you want to set your crawl rate for Googlebot, you’ll have to do it in Search Console.
Bing and Yandex, on the other hand, do support the crawl-delay directive. Here’s how to use it.
Let’s say you want a crawler to wait 10 seconds after each crawl action. Set the delay to 10, like so:
User-agent: *
Crawl-delay: 10Noindex Directive
The robots.txt file tells a bot what it can or can’t crawl, but it can’t tell a search engine which URLs not to index and show in search results.
The page will still show up in search results, but the bot won’t know what’s on it, so your page will appear like this:
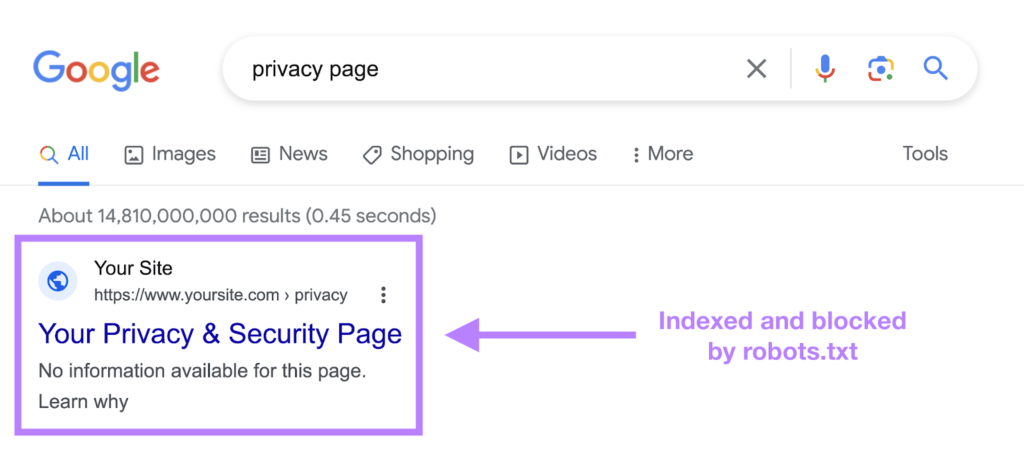
Google never officially supported this directive, but on September 1, 2019, Google announced that this directive is not supported.
If you want to reliably exclude a page or file from appearing in search results, avoid this directive altogether and use a meta robots noindex tag.
How to Create a Robots.txt File
Use a robots.txt generator tool or create one yourself.
Here’s how:
1. Create a File and Name It Robots.txt
Start by opening a .txt document within a text editor or web browser.
Note: Don’t use a word processor, as they often save files in a proprietary format that can add random characters.
Next, name the document robots.txt.
Now you’re ready to start typing directives.
2. Add Directives to the Robots.txt File
A robots.txt file consists of one or more groups of directives, and each group consists of multiple lines of instructions.
Each group begins with a “user-agent” and has the following information:
- Who the group applies to (the user-agent)
- Which directories (pages) or files the agent can access
- Which directories (pages) or files the agent can’t access
- A sitemap (optional) to tell search engines which pages and files you deem important
Crawlers ignore lines that don’t match these directives.
For example, let’s say you don’t want Google crawling your /clients/ directory because it’s just for internal use.
The first group would look something like this:
User-agent: Googlebot
Disallow: /clients/Additional instructions can be added in a separate line below, like so:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-googleOnce you’re done with Google’s specific instructions, hit enter twice to create a new group of directives.
Let’s make this one for all search engines and prevent them from crawling your /archive/ and /support/ directories because they’re for internal use only.
It would look like this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/Once you’re finished, add your sitemap.
Your finished robots.txt file would look something like this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xmlSave your robots.txt file. Remember, it must be named robots.txt.
Note: Crawlers read from top to bottom and match with the first most specific group of rules. So, start your robots.txt file with specific user agents first, and then move on to the more general wildcard (*) that matches all crawlers.
3. Upload the Robots.txt File
After you’ve saved the robots.txt file to your computer, upload it to your site and make it available for search engines to crawl.
Unfortunately, there’s no universal tool for this step.
Uploading the robots.txt file depends on your site’s file structure and web hosting.
Search online or reach out to your hosting provider for help on uploading your robots.txt file.
For example, you can search for “upload robots.txt file to WordPress.”
Below are some articles explaining how to upload your robots.txt file in the most popular platforms:
- Robots.txt file in WordPress
- Robots.txt file in Wix
- Robots.txt file in Joomla
- Robots.txt file in Shopify
- Robots.txt file in BigCommerce
After uploading, check if anyone can see it and if Google can read it.
Here’s how.
4. Test Your Robots.txt
First, test whether your robots.txt file is publicly accessible (i.e., if it was uploaded correctly).
Open a private window in your browser and search for your robots.txt file.
For example, https://skbdev.com/robots.txt.
If you see your robots.txt file with the content you added, you’re ready to test the markup (HTML code).
Google offers two options for testing robots.txt markup:
- The robots.txt Tester in Search Console
- Google’s open-source robots.txt library (advanced)
Because the second option is geared toward advanced developers, let’s test your robots.txt file in Search Console.
Note: You must have a Search Console account set up to test your robots.txt file.
Go to the robots.txt Tester and click on “Open robots.txt Tester.”
If you haven’t linked your website to your Google Search Console account, you’ll need to add a property first.
Then, verify you are the site’s real owner.
Note: Google is planning to shut down this setup wizard. So in the future, you’ll have to directly verify your property in the Search Console. Read our full guide to Google Search Console to learn how.
If you have existing verified properties, select one from the drop-down list on the Tester’s homepage.
The Tester will identify syntax warnings or logic errors.
And display the total number of warnings and errors below the editor.

You can edit errors or warnings directly on the page and retest as you go.
Any changes made on the page aren’t saved to your site. The tool doesn’t change the actual file on your site. It only tests against the copy hosted in the tool.
To implement any changes, copy and paste the edited test copy into the robots.txt file on your site.
Robots.txt Best Practices
Use New Lines for Each Directive
Each directive should sit on a new line.
Otherwise, search engines won’t be able to read them, and your instructions will be ignored.
Incorrect:
User-agent: * Disallow: /admin/
Disallow: /directory/Correct:
User-agent: *
Disallow: /admin/
Disallow: /directory/Use Each User-Agent Once
Bots don’t mind if you enter the same user-agent multiple times.
But referencing it only once keeps things neat and simple. And reduces the chance of human error.
Confusing:
User-agent: Googlebot
Disallow: /example-page
User-agent: Googlebot
Disallow: /example-page-2Notice how the Googlebot user-agent is listed twice.
Clear:
User-agent: Googlebot
Disallow: /example-page
Disallow: /example-page-2In the first example, Google would still follow the instructions and not crawl either page.
But writing all directives under the same user-agent is cleaner and helps you stay organized.
Use Wildcards to Clarify Directions
You can use wildcards (*) to apply a directive to all user-agents and match URL patterns.
For example, to prevent search engines from accessing URLs with parameters, you could technically list them out one by one.
But that’s inefficient. You can simplify your directions with a wildcard.
Inefficient:
User-agent: *
Disallow: /shoes/vans?
Disallow: /shoes/nike?
Disallow: /shoes/adidas?Efficient:
User-agent: *
Disallow: /shoes/*?The above example blocks all search engine bots from crawling all URLs under the /shoes/ subfolder with a question mark.
Use ‘$’ to Indicate the End of a URL
Adding the “$” indicates the end of a URL.
For example, if you want to block search engines from crawling all .jpg files on your site, you can list them individually.
But that would be inefficient.
Inefficient:
User-agent: *
Disallow: /photo-a.jpg
Disallow: /photo-b.jpg
Disallow: /photo-c.jpgInstead, add the “$” feature, like so:
Efficient:
User-agent: *
Disallow: /*.jpg$Note: In this example, /dog.jpg can’t be crawled, but /dog.jpg?p=32414 can be because it doesn’t end with “.jpg.”
The “$” expression is a helpful feature in specific circumstances such as the above. But it can also be dangerous.
You can easily unblock things you didn’t mean to, so be prudent in its application.
Use the Hash (#) to Add Comments
Crawlers ignore everything that starts with a hash (#).
So, developers often use a hash to add a comment in the robots.txt file. It helps keep the file organized and easy to read.
To add a comment, begin the line with a hash (#).
Like this:
User-agent: *
#Landing Pages
Disallow: /landing/
Disallow: /lp/
#Files
Disallow: /files/
Disallow: /private-files/
#Websites
Allow: /website/*
Disallow: /website/search/*Developers occasionally include funny messages in robots.txt files because they know users rarely see them.
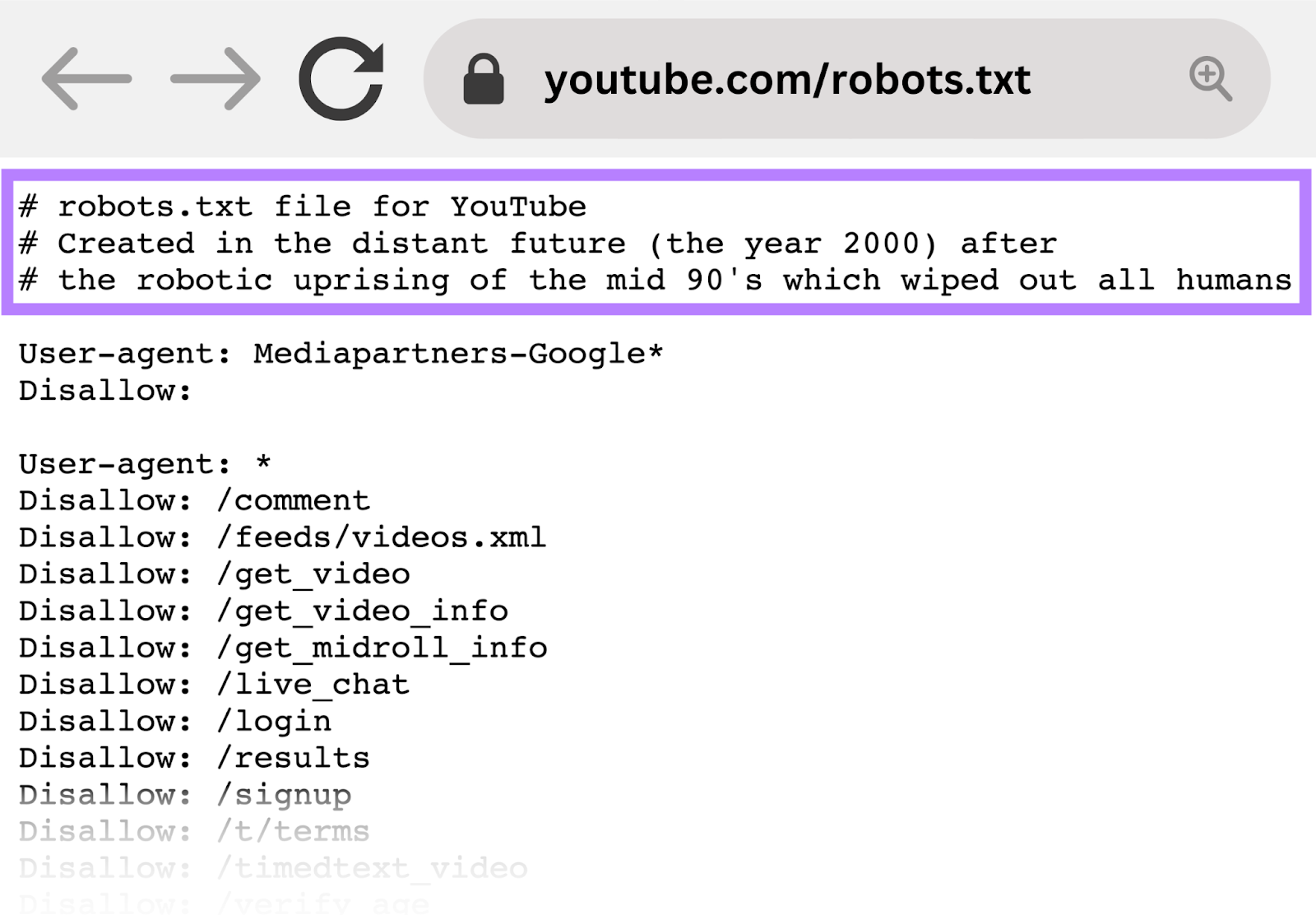
For example, YouTube’s robots.txt file reads: “Created in the distant future (the year 2000) after the robotic uprising of the mid 90’s which wiped out all humans.”
And Nike’s robots.txt reads “just crawl it” (a nod to its “just do it” tagline) and its logo.

Use Separate Robots.txt Files for Different Subdomains
Robots.txt files control crawling behavior only on the subdomain in which they’re hosted.
To control crawling on a different subdomain, you’ll need a separate robots.txt file.
So, if your main site lives on domain.com and your blog lives on the subdomain blog.domain.com, you’d need two robots.txt files.
One for the main domain’s root directory and the other for your blog’s root directory.
For more know contact us.
















naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
This was beautiful Admin. Thank you for your reflections.
you are in reality a good webmaster The website loading velocity is amazing It sort of feels that youre doing any distinctive trick Also The contents are masterwork you have done a fantastic job in this topic
Hi my family member, I want to mention that this post is excellent, well-written, and full of important stuff. I would like to see more posts like this
I loved it as much as you’ll end it here. The sketch and writing are good, but you’re nervous about what comes next. Definitely come back because it’s pretty much always the same if you protect this walk.
Lovely! This has been an absolutely fantastic post. I appreciate you sharing these specifics.
Thanks-a-mundo for the post.Really thank you! Awesome.
My website: порно массаж
hiI like your writing so much share we be in contact more approximately your article on AOL I need a specialist in this area to resolve my problem Maybe that is you Looking ahead to see you
Your posts always provide me with a new perspective and encourage me to look at things differently Thank you for broadening my horizons
Zaproxy dolore alias impedit expedita quisquam.
I’ve been following this blog for years and it’s amazing to see how much it has grown and evolved Congratulations on all your success!
Keep up the fantastic work!
Every time I read a new post, I feel like I’ve learned something valuable or gained a new perspective. Thank you for consistently putting out such great content!
Your blog is a treasure trove of wisdom and positivity I appreciate how you always seem to know just what your readers need to hear
Share with us in the comments your favorite blog posts of all time!
Your words have resonated with us and we can’t wait to read more of your amazing content. Thank you for sharing your expertise and passion with the world.
Keep up the incredible work! I can’t wait to see what you write next.
Your words have a way of resonating deeply with your readers Thank you for always being encouraging and uplifting
Keep up the amazing work! Can’t wait to see what you have in store for us next.
I love how this blog gives a voice to important social and political issues It’s important to use your platform for good, and you do that flawlessly
What topics would you like to see covered in future posts? Let us know in the comments.
Your photography and visuals are always so stunning They really add to the overall quality of the content
Your blog post had me hooked from the very beginning!
Your writing is so powerful and has the ability to make a real difference in people’s lives Keep using your voice to spread kindness and positivity
I truly admire how you tackle difficult topics and address them in a respectful and thought-provoking manner
Your blog has been a constant source of support and encouragement for me I am grateful for your words of wisdom and positivity
It’s always a joy to stumble upon content that genuinely makes an impact and leaves you feeling inspired. Keep up the great work!
Your words have resonated with us and we can’t wait to read more of your amazing content. Thank you for sharing your expertise and passion with the world.
Looking forward to your next post. Keep up the good work!
From the bottom of my heart, thank you for being a source of positivity and light in this sometimes dark and overwhelming world
Your writing has a way of resonating with me and making me feel understood Thank you for being a relatable and authentic voice
Your honesty and vulnerability in sharing your personal experiences is truly admirable It takes courage to open up and I applaud you for it
What type of content would you like to see more of in the future? Let us know in the comments!
Your latest blog post was truly inspiring and had some great insights. I can’t wait to see what else you have in store.
Your positivity and enthusiasm are contagious Reading your blog has become a part of my daily routine and I always leave feeling better than when I arrived
The photographs and visuals used in this blog are always stunning They really add a beautiful touch to the posts
I am constantly impressed by the depth and detail in your posts You have a gift for making complex topics easily understandable
This blog is a great mix of informative and entertaining content It keeps me engaged and interested from start to finish
What topics would you like to see covered in future posts? Let us know in the comments.
This blog has become a part of my daily routine I start my mornings with a cup of coffee and your latest post
Your blog post had me hooked from the very beginning!
Thank you for always being open and honest with your readers It’s refreshing to see a blogger who is unafraid to be vulnerable and real
From start to finish, this blog post had us hooked. The content was insightful, entertaining, and had us feeling grateful for all the amazing resources out there. Keep up the great work!
Your content always manages to captivate and educate me. Keep up the fantastic work!
What topics would you like to see covered in future posts? Let us know in the comments.
From the insightful commentary to the captivating writing, every word of this post is top-notch. Kudos to the author for producing such fantastic content.
This post was exactly what I needed to read today Your words have provided me with much-needed clarity and reassurance
Every time I read one of your posts, I come away with something new and interesting to think about. Thanks for consistently putting out such great content!
I appreciate the effort that goes into creating high-quality content, and this post was no exception. The insights and information were top-notch and made for a really engaging read. Keep up the great work!
Your posts are so well-written and eloquent It’s impossible not to be moved by your words Keep using your voice to spread positivity
This blog is like a virtual mentor, guiding me towards personal and professional growth Thank you for being a source of inspiration
I appreciate how well-researched and informative each post is It’s obvious how much effort you put into your work
Your writing is a breath of fresh air It’s clear that you put a lot of thought and effort into each and every post
Your posts always leave me feeling motivated and empowered You have a gift for inspiring others and it’s evident in your writing
Your words have a way of resonating deeply with your readers Thank you for always being encouraging and uplifting
This post was exactly what I needed to read today Your words have provided me with much-needed clarity and reassurance
Wow, this blogger is seriously impressive!
I appreciate your creativity and the effort you put into every post. Keep up the great work!
I am constantly impressed by the depth and detail in your posts You have a gift for making complex topics easily understandable
I appreciate how well-researched and detailed your posts are It’s evident that you put a lot of time and effort into providing valuable information to your readers
I appreciate how this blog promotes self-growth and personal development It’s important to continuously strive to become the best version of ourselves
Your writing style is so engaging and easy to follow I find myself reading through each post without even realizing I’ve reached the end
Your posts are so thought-provoking and often leave me pondering long after I have finished reading Keep challenging your readers to think outside the box
I truly admire how you tackle difficult topics and address them in a respectful and thought-provoking manner
Your blog has become a source of guidance and support for me Your words have helped me through some of my toughest moments
Your writing has a way of making complicated topics easier to understand It’s evident how much research and effort goes into each post
Your vulnerability and honesty in your posts is truly admirable Thank you for being so open and authentic with your readers
I truly admire how you tackle difficult topics and address them in a respectful and thought-provoking manner
Your positivity and optimism are contagious It’s evident that you genuinely care about your readers and their well-being
Your vulnerability and honesty in your posts is truly admirable Thank you for being so open and authentic with your readers
I love how this blog covers a variety of topics, making it appeal to a diverse audience There is something for everyone here!
Your writing is so genuine and heartfelt It’s refreshing to read a blog that is not trying to sell something or promote an agenda
Your words have resonated with us and we can’t wait to read more of your amazing content. Thank you for sharing your expertise and passion with the world.
As a new reader, I am blown away by the quality and depth of your content I am excited to explore your past posts and see what else you have to offer
It’s clear that you truly care about your readers and want to make a positive impact on their lives Thank you for all that you do
As a fellow blogger, I can appreciate the time and effort that goes into creating well-crafted posts You are doing an amazing job
This is such an informative and well-written post! I learned a lot from reading it and will definitely be implementing some of these tips in my own life
Your blog post was really enjoyable to read, and I appreciate the effort you put into creating such great content. Keep up the great work!
Your positivity and enthusiasm are contagious Reading your blog has become a part of my daily routine and I always leave feeling better than when I arrived
Your blog has quickly become one of my favorites I always look forward to your new posts and the insights they offer
Your positivity and optimism are contagious It’s evident that you genuinely care about your readers and their well-being
Keep up the incredible work! I can’t wait to see what you write next.
I always look forward to reading your posts, they never fail to brighten my day and educate me in some way Thank you!
Your writing style is so engaging and makes even the most mundane topics interesting to read Keep up the fantastic work
Your posts always leave me feeling motivated and empowered You have a gift for inspiring others and it’s evident in your writing
The topics covered here are always so interesting and unique Thank you for keeping me informed and entertained!
The positivity and optimism conveyed in this blog never fails to uplift my spirits Thank you for spreading joy and positivity in the world
The topics covered here are always so interesting and unique Thank you for keeping me informed and entertained!
Your posts always seem to lift my spirits and remind me of all the good in the world Thank you for being a beacon of positivity
Your words have resonated with us and we can’t wait to read more of your amazing content. Thank you for sharing your expertise and passion with the world.
Your blog is an oasis in a world filled with negativity and hate Thank you for providing a safe space for your readers to recharge and refuel
Your vulnerability and honesty in your posts is truly admirable Thank you for being so open and authentic with your readers
Your writing style is so engaging and easy to follow I find myself reading through each post without even realizing I’ve reached the end
Their posts always leave us feeling informed and entertained. We’re big fans of their style and creativity.
Your writing is so powerful and has the ability to make a real difference in people’s lives Keep using your voice to spread kindness and positivity
Your positivity and optimism are contagious It’s impossible to read your blog without feeling uplifted and inspired Keep up the amazing work
Your posts are so beautifully written and always leave me feeling inspired and empowered Thank you for using your talents to make a positive impact
This blog post has left us feeling grateful and inspired
Your posts are so beautifully written and always leave me feeling inspired and empowered Thank you for using your talents to make a positive impact
Your writing has a way of making complicated topics easier to understand It’s evident how much research and effort goes into each post
The topics covered here are always so interesting and unique Thank you for keeping me informed and entertained!
Thank you for sharing your personal experience and wisdom with us Your words are so encouraging and uplifting
As a fellow blogger, I can appreciate the time and effort that goes into creating well-crafted posts You are doing an amazing job
Your blog is an oasis in a world filled with negativity and hate Thank you for providing a safe space for your readers to recharge and refuel
Your vulnerability and honesty in your posts is truly admirable Thank you for being so open and authentic with your readers
Leave a comment and let us know what your favorite blog post has been so far!
Your blog is so much more than just a collection of posts It’s a community of like-minded individuals spreading optimism and kindness
Keep up the amazing work! Can’t wait to see what you have in store for us next.
Share with us in the comments your favorite blog posts of all time!
Keep up the amazing work! Can’t wait to see what you have in store for us next.
Love this blog! The content is always so relevant and insightful, keep up the great work!
Your positivity and enthusiasm are contagious Reading your blog has become a part of my daily routine and I always leave feeling better than when I arrived
Thank you for creating such valuable content. Your hard work and dedication are appreciated by so many.
I love how this blog promotes self-love and confidence It’s important to appreciate ourselves and your blog reminds me of that
This blog is not just about the content, but also the community it fosters I’ve connected with so many like-minded individuals here
I love how this blog gives a voice to important social and political issues It’s important to use your platform for good, and you do that flawlessly
This blog post is worth the read – trust us!
Your writing has a way of resonating with me and making me feel understood Thank you for being a relatable and authentic voice
Your posts always provide me with a new perspective and encourage me to look at things differently Thank you for broadening my horizons
Your positivity and optimism are contagious It’s impossible to read your blog without feeling uplifted and inspired Keep up the amazing work
Their posts always leave us feeling informed and entertained. We’re big fans of their style and creativity.
Looking forward to your next post. Keep up the good work!
Your positivity and enthusiasm are contagious Reading your blog has become a part of my daily routine and I always leave feeling better than when I arrived
This post hits close to home for me and I am grateful for your insight and understanding on this topic Keep doing what you do
Your posts are so well-written and eloquent It’s impossible not to be moved by your words Keep using your voice to spread positivity
Your positivity and optimism are contagious It’s impossible to read your blog without feeling uplifted and inspired Keep up the amazing work
Your posts always make me feel like I’m not alone in my struggles and insecurities Thank you for sharing your own experiences and making me feel understood
Keep up the amazing work! Can’t wait to see what you have in store for us next.
I love how this blog promotes a healthy and balanced lifestyle It’s a great reminder to take care of our bodies and minds
I couldn’t stop scrolling and reading, your content is truly one-of-a-kind. Thank you for all the time and effort you put into creating such amazing content.
Your positivity and enthusiasm are contagious Reading your blog has become a part of my daily routine and I always leave feeling better than when I arrived
Thank you for sharing your personal experiences and stories It takes courage to open up and you do it with such grace and authenticity
Keep up the amazing work! Can’t wait to see what you have in store for us next.
Your writing is so eloquent and engaging You have a gift for connecting with your readers and making us feel understood
I love how this blog gives a voice to important social and political issues It’s important to use your platform for good, and you do that flawlessly
This post is jam-packed with valuable information and I appreciate how well-organized and easy to follow it is Great job!
This web site is my inhalation, very wonderful layout and perfect subject matter.
I gotta favorite this site it seems very beneficial handy
My website: анилингус порно
Respect to post author, some fantastic information
My website: chastnoeporno
An intriguing discussion is worth comment. I believe that you
ought to write more on this topic, it might not be a taboo subject but typically people don’t talk about such subjects.
To the next! All the best!!
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away your
intelligence on just posting videos to your weblog when you could be giving us something informative to read?
Quality articles is the main to invite the people to
pay a quick visit the site, that’s what this web site is providing.
Нi to еvery body, it’s my first pay a qᥙіck νisit of this blog; this webpage includes remarkаƄle and
genuinely fine mɑterial for visitors.
FlixHQ With the admin’s efforts, it’s clear this site will soon be well-known for its excellent content.